12月5日消息,今日,火山引擎发布豆包语音识别模型2.0(Doubao-Seed-ASR-2.0),依托Seed混合专家大语言模型架构构建。
据介绍,2.0版本模型推理能力提升,可以通过深度理解上下文完成精准识别,上下文整体关键词召回率提升20%。
同时支持多模态视觉识别,不仅“听懂字”还能“看懂图”,通过单图和多图等视觉信息输入让文字识别更精准。

此外,2.0版本还支持日语、韩语、德语、法语等 13 种海外语种的精准识别。
并且重点针对专有名词、人名、地名、品牌名称及易混淆多音字等复杂场景进行了升级。
以历史人物生平讨论场景为例,当用户提及苏辙贬谪地“筠(yún)州”时,如果模型缺乏推理能力会易将其误识别为同音的“云州”“郓州”等。
而豆包语音识别模型2.0可依托“当前讨论苏轼、苏辙”这一背景,即便上下文从没出现过“筠州”,也能通过逻辑推理锁定用户所指的特定地名,最终实现对多音字地名的精准识别。
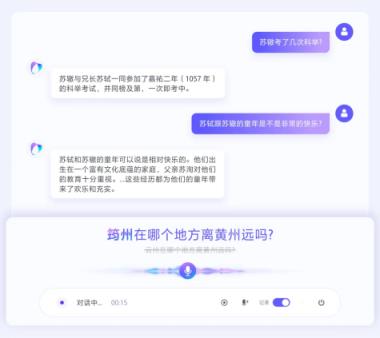
目前,豆包语音识别模型2.0已上线火山方舟体验中心并对外提供API服务。

本文转载于快科技,文中观点仅代表作者个人看法,本站只做信息存储
本文来自于网络或用户投稿,本站仅供信息存储,阅读前请先查看【免责声明】,若本文侵犯了原著者的合法权益,可联系我们进行处理。本文链接:https://trustany.com/post/19504.html